Data coding in research is the process of identifying, labelling and organising meaning within qualitative material so that large volumes of conversation can be examined systematically. Codes are assigned to sections of transcripts and notes, to capture what is being expressed, how often it appears and how it connects to other ideas. This turns raw conversations, like focus group sessions or research interviews, into a structured set of themes that can be revisited and interpreted across participants and sessions, without losing original meaning.
Traditional data coding vs AI-enabled data coding in research
Traditionally, data coding was carried out manually inside qualitative analysis tools or documents, with researchers reading through transcripts line-by-line and applying predefined labels to passages of text. These labels were often broad and descriptive, such as “positive”, “negative”, or “neutral”, and relied heavily on the researcher’s judgement. This approach allows for careful interpretation, but can be slow, difficult to scale and potentially open to bias.
AI-enabled coding builds on this foundation by supporting early stages of the process. Rather than manually tagging, AI reads and interprets transcripts at speed, surfaces patterns and applies internal codes that help organise the data for return. Whilst AI tools don’t always apply traditional code “tags”, the underlying mechanism is the same. This method provides an internal structure that researchers can work with directly by asking for interpretation, without having to label each passage by hand.
What makes data coding difficult in practice?
The early stages of traditional data coding take time because the researcher is moving through unfamiliar material and making calls about which passages matter and which do not. Some sections hold clear insight, others drift, and it is not always obvious which parts deserve attention on the first pass. The meaning of the study has not been settled yet, so each decision relies on instinct rather than a stable structure.
Consistency becomes harder as the study grows. Codes shift as the researcher gains a better sense of the topic, which means earlier decisions often need refining so everything aligns. When several researchers contribute to the same project, this becomes even more complex because each person may interpret a line in a slightly different way.
AI can make this easier by scanning large volumes of transcript material at once, rather than a single interview at a time. AI can spot recurring themes, and codes across the full body of material, rather than in situ.
Finally, volume adds pressure as well. Long interviews produce more material than anyone can hold in mind, and it becomes difficult to track where certain ideas appeared or how they changed over time. Revisiting transcripts helps, but it stretches the timeline of the study and slows progress towards interpretation.
How to do data coding in research using Beings
Beings is an AI co-partner tool for qualitative research. Beings handles data coding differently to traditional qualitative analysis tools. Instead of manually tagging passages inside the transcript, Beings’ AI tool Aida, is able to classify all material at once from uploaded text, audio and PDF files. This allows researchers to work through prompts, summaries, and evidence extraction using conversational AI. Here’s how to get started using Beings for coding your data:
1) Start by generating themes from the transcript
Upload your recording to Beings or invite Aida directly to your call, in order to generate the transcript. Once the transcript is ready, you can ask Aida to explore the themes in the session. A simple prompt is usually enough to surface an initial structure, for example:
“Explore the key themes in this transcript and include short definitions with supporting quotes.”
Beings responds with themes, brief explanations, and evidence pulled directly from the conversation. This gives you a clear starting point for coding without needing to decide on tags or structure upfront.
2) Review the suggested coding tags (if required)
Beings uses internal coding tags to organise material as a whole, without requiring the researcher to manage labels directly, which helps protect nuance within a study. If coding tags are required for client or reporting purposes, the researcher can ask Beings to surface a provisional list based on the patterns identified in the entire body of research or transcript. These tags reflect the main ideas present in the conversation and provide a working code list that can be refined over time.
A simple prompt to gain coding tags within the data might be:
“Based on these themes, suggest a set of coding tags I can use for analysis.”Once the tags are returned, you review the list and decide whether the wording and scope match the focus of your study.
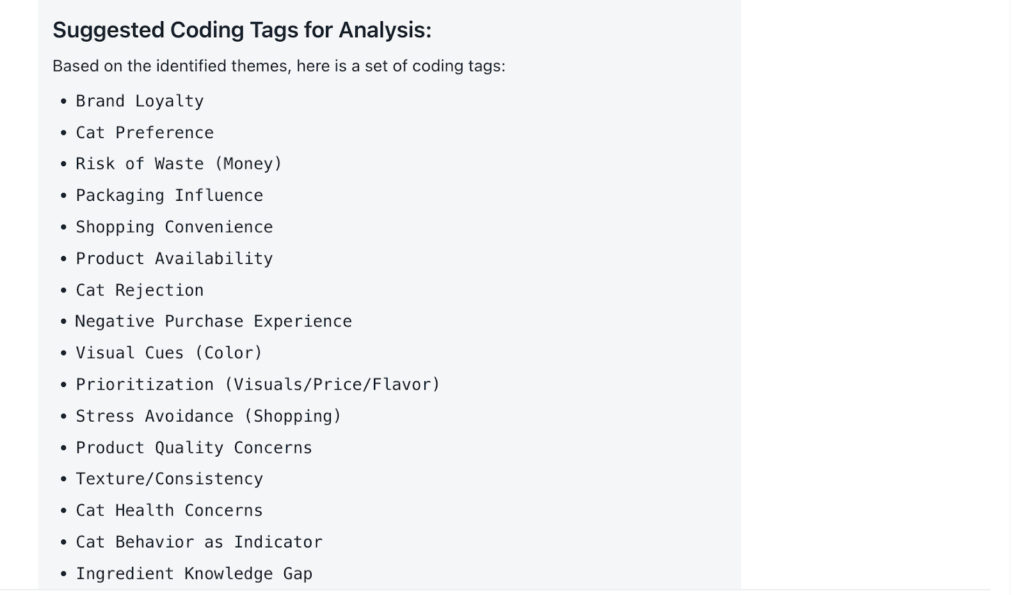
3) Refine the tags using your own judgement
After reviewing the suggested tags, the researcher can ask Aida to merge or change the naming conventions where needed. Tags that overlap in meaning can be combined into a smaller set, or set aside altogether if the analysis is moving forward at a thematic level rather than through formal labels.
For example, the researcher might ask Beings to group tags linked to preference, request that risk groupings be combined into a single category, or decide that tags related to packaging and visual cues can be grouped together.
4) Extract and review evidence using the refined tags
Once the tags are refined, you can ask Beings to pull together all the parts of the transcript linked to a specific tag. Instead of scanning the transcript manually, the system recalls the internal classification and presents the relevant quotes with context and timestamps, taking you directly to the point of audio in the source material.
This step helps you check whether a tag is doing useful work. If the extracted material feels scattered or unfocused, the tag may still be too broad and worth refining further. If the material holds together, you can move on knowing the structure is sound.
5) Summarise insights to move from coding to interpretation
Once the evidence under a tag has been reviewed, the focus shifts from what was said to what it suggests. Summarising data codes helps clarify how an idea shows up in the session, how strongly it is expressed, and how it connects to the wider research question.
At this stage, each tag begins to carry meaning rather than just content. The summary becomes a reference point that can be compared across transcripts, helping to surface differences and patterns as the project grows. This is where coding stops being a way to organise material and starts to support the interpretation and decision making.
As more sessions are added, these summaries make it easier to step back from individual conversations and understand how themes are forming across the project as a whole.
FAQs on coding qualitative data
What does data coding mean in research?
Data coding is the term used to label sections of material so they can be examined in a structured way. In qualitative research, this usually involves marking and attaching codes to sections of speech, ideas or even phrases that help to explain, like motivation or expectations. It’s also used in quantitative research by grouping numerical data into categories that can be analysed.
Why should qualitative researchers use data coding?
Data coding helps researchers to manage the material in an organised way. Most research is going to be spoken word or written text, so data coding is a systematic way you can tag or label sections of text to identify themes. It makes it easier to get a bird’s eye view of what is being said, and makes it easier to compare different parts of a project as a whole.
Should everything be data coded?
No. The point of data coding is to find the most important parts that are relevant to the outcomes. While it may be tempting to code everything, this adds unnecessary work and adds noise to a project. Focus on the parts that move the study forward, and you can always revisit again.
Does AI remove the need for manual coding?
In many cases, yes. Beings can organise the qualitative data into themes without requiring researchers to manually tag transcripts, which reduces the mechanical coding work. Manual coding remains valuable where projects need predefined categories or strict reporting procedures, but in many studies, the AI can handle the initial organisation so researchers can spend their time interpreting meaning rather than labelling text.
How does coding work inside Beings?
Coding in Beings is handled internally by the system. Rather than manually tagging passages, researchers interact with the results of that coding through conversational analysis, theme exploration, evidence extraction and working with summaries that reflect how the material has been classified.
Start Exploring Data Coding in Beings
Try this approach on your own research by creating a free Beings account. Simply upload a recent interview or invite Beings to your next call and start exploring themes and uncovering insights.
Working through one session is often enough to see how internal classification and evidence extraction support coding, without the need for manual tagging.