For many researchers, the pull of tools like ChatGPT is easy to understand. You are staring at hours of transcripts, messy notes from fieldwork, half-formed themes, and a deadline that is not moving. A free, easily-accessible AI tool promises speed and ease – paste in a chunk of text, ask a sensible question and something coherent comes back. It feels helpful and neutral, with a level of polish that can be surprisingly convincing.
That convenience hides a decision most researchers do not realise they are making. When you use a general AI tool for research, you are not just choosing how analysis happens. You are choosing where your data is processed, which laws apply to it, and whether you still control it once it leaves your screen.
This is where Beings and ChatGPT diverge.
ChatGPT is a public, cloud-based, general-purpose tool that happens to be used for research. Beings is a private qualitative research environment, built for UK-regulated work, where data containment and data sovereignty are foundational parts of the system design.
That difference matters more than many research teams realise.
What is data sovereignty, and why does it matter for researchers?
Data sovereignty is the idea that data is governed by the laws of the country where it is collected, stored, and processed. When research data stays within the UK, it remains subject to UK data protection law, regulatory oversight, and established routes for redress. Once it crosses a border, it becomes subject to a different legal system, different expectations, and different rules about access and retention.
For qualitative researchers, this is not abstract. Transcripts and open-ended responses often contain lived experience, opinion, and context that can be re-identified more easily than many teams expect. Client-commissioned research also entails contractual obligations regarding confidentiality and handling that extend beyond baseline GDPR compliance.
Data sovereignty is about whether researchers can clearly account for how that material is treated once it leaves their control.

AI makes this harder to see. For most ChatGPT users, data is processed on OpenAI’s global infrastructure, usually in the United States. UK and EU data residency only applies where an organisation has explicitly paid for and configured a regional setup. Even where model training is disabled, data still moves through systems governed by non-UK legal frameworks, usually without the researcher having visibility into that journey.
Responsibility, though, does not disappear. Agencies remain accountable to participants, clients, ethics boards, and regulators for how data is handled across the research lifecycle. Data sovereignty provides a way to keep control and accountability aligned, rather than discovering after the fact that sensitive material has travelled further than anyone intended.
Why ChatGPT is a poor fit for sensitive qualitative research
When researchers paste transcripts or notes into ChatGPT, it is easy to assume the tool is behaving like a smart notepad. Text goes in, analysis comes out, and the exchange feels momentary. In reality, that is not how large-scale AI systems work.
ChatGPT is a cloud-based system. Any data entered into it is transmitted from the user’s device to remote servers, where it is processed by large models running across distributed infrastructure. That infrastructure is global by design. Data may be routed, cached, or processed in locations outside the UK, potentially outside the EU. The user rarely sees where this happens, or which legal jurisdiction applies at each step.
In order to generate a response, the data is transformed and handled by the system. Even when model training is disabled, transient copies may exist for processing, logging, or system reliability. From the researcher’s point of view, this all happens behind a clean interface that offers no indication of movement, duplication, or retention.
These tools are also general-purpose. ChatGPT does not recognise when text comes from ethically approved research, client-commissioned studies, or regulated environments. Participant context, contractual boundaries, and jurisdictional sensitivity are invisible to the system. All input is treated in the same way, regardless of how that material was collected or who remains accountable for it.
Risk in qualitative research often emerges through accumulation rather than obvious identifiers. A single quote may feel harmless. A set of responses, read together, can reveal far more than intended. When that material is processed inside a public cloud AI environment, researchers no longer control how those connections are made or where that processing takes place.
For agencies, this creates risk. Early-stage analysis is frequently handled by junior team members working under time pressure. Public AI tools make it easy for sensitive material to be analysed outside approved systems, without consistent oversight. The result is rarely deliberate misuse, but a widening gap between everyday practice and the level of control clients expect.
ChatGPT remains useful for drafting, ideation, and general reasoning. Sensitive qualitative research raises different questions about responsibility, visibility, and jurisdiction, questions that public cloud tools were never designed to answer.
Private data vs public cloud AI
Many research teams use paid business versions of ChatGPT, which state that customer inputs and outputs are not used to train shared models by default. That commitment matters, and it does reduce one category of risk that researchers care about.
Training, though, is only one part of the data journey. Even when data is excluded from model improvement, it is still transmitted to, processed by, and handled within infrastructure operated by a third party. The researcher does not run the model locally, does not control the underlying systems, and does not directly govern how that environment evolves. Access, retention, and handling are shaped by service terms and technical architecture rather than by the research team itself.
Private research environments take a different approach. They aim to limit data movement by design, keep jurisdiction explicit, and reduce reliance on future policy decisions made elsewhere. When data stays within the UK, it remains subject to UK law, UK oversight, and UK routes for challenge if something goes wrong.
For researchers and agencies, the key questions are where their data sits, which laws apply, and who ultimately controls the systems processing it. That clarity is what separates private research infrastructure from public cloud convenience.
Why Beings AI is built differently from ChatGPT
The difference between Beings AI and ChatGPT begins with design intent.
Beings was created for qualitative research teams working with live, sensitive material, often under contractual, ethical, or regulatory constraints. From the outset, decisions about data handling, storage, and processing were treated as core architectural choices rather than secondary safeguards. The system assumes that research data belongs to the agency and its clients, and that responsibility for that data does not disappear simply because AI is involved.
ChatGPT comes from a different place. It is a general-purpose system designed to support a wide range of everyday tasks across industries and geographies. Research is one of many possible uses, not the organising principle. That breadth means that research-specific requirements around jurisdiction, participant protection, and auditability are not embedded into how the system operates by default.
How Beings creates a strict, private environment for AI use in research
Beings takes a narrower path by choice. It is designed to keep research data contained, visible, and governed within a defined context. Data sovereignty is treated as a starting condition rather than a preference the user has to configure or remember to apply. Data movement is made explicit, unnecessary exposure is limited, and researchers are supported in explaining their methods and safeguards to clients, auditors, and regulators.
This difference shapes how the AI behaves in practice.
Beings is created for research
Aida is Beings’ built-in research AI co-partner, designed specifically for qualitative analysis rather than general conversation. Aida operates inside a closed project space and restricts the analysis to the material the researcher has provided. It does not pull in outside sources or blend external assumptions into the analysis. Insight stays grounded in the evidence collected, which matters when findings need to be defended rather than explored informally.
This is a deliberate analytical stance rather than a side effect of configuration. Aida operates on a ground truth principle. Its analysis is restricted to the Project Corpus the researcher uploads, not to external knowledge, inferred context, or general world information. Unlike generic AI tools that may introduce outside assumptions or background bias, Aida’s default state is to work only with the evidence in front of it. For researchers, this reduces the need for defensive prompting. You do not have to repeatedly instruct the system to ignore outside knowledge or to stay within the bounds of the data. That constraint is built in from the start.
Unlike general-purpose chat tools, Aida does not need to be instructed to think like a researcher. It is designed to apply established qualitative reasoning by default, including tracing the red thread of evidence across a dataset, how ideas develop, recur, and connect across participants, questions, and contexts. Prompts are used to direct analytical focus, not to correct the AI’s underlying approach.
Beings allows for negative evidence prompts
Aida is also designed to treat negative evidence as analytically meaningful. Rather than collapsing responses into an average or dominant view, it surfaces disagreement, outliers, and contradictory accounts where they appear. This supports a more rigorous interpretation by showing not only what is common but also where findings are contested or unstable.
Beings links all findings back to the exact source material – by timestamp
Analysis takes place directly alongside the source material rather than after it has been copied into a separate workspace. As Aida works, every reference it draws on is surfaced in context, with one or multiple citations shown for each claim or insight. Researchers can click straight through to the exact passages Aida is using, see how different sources contribute to the same conclusion, and trace reasoning back to the original material without guesswork. This makes review, collaboration, and audit straightforward because teams are looking at the same evidence, in the same place, with a clear line between source, interpretation, and outcome.
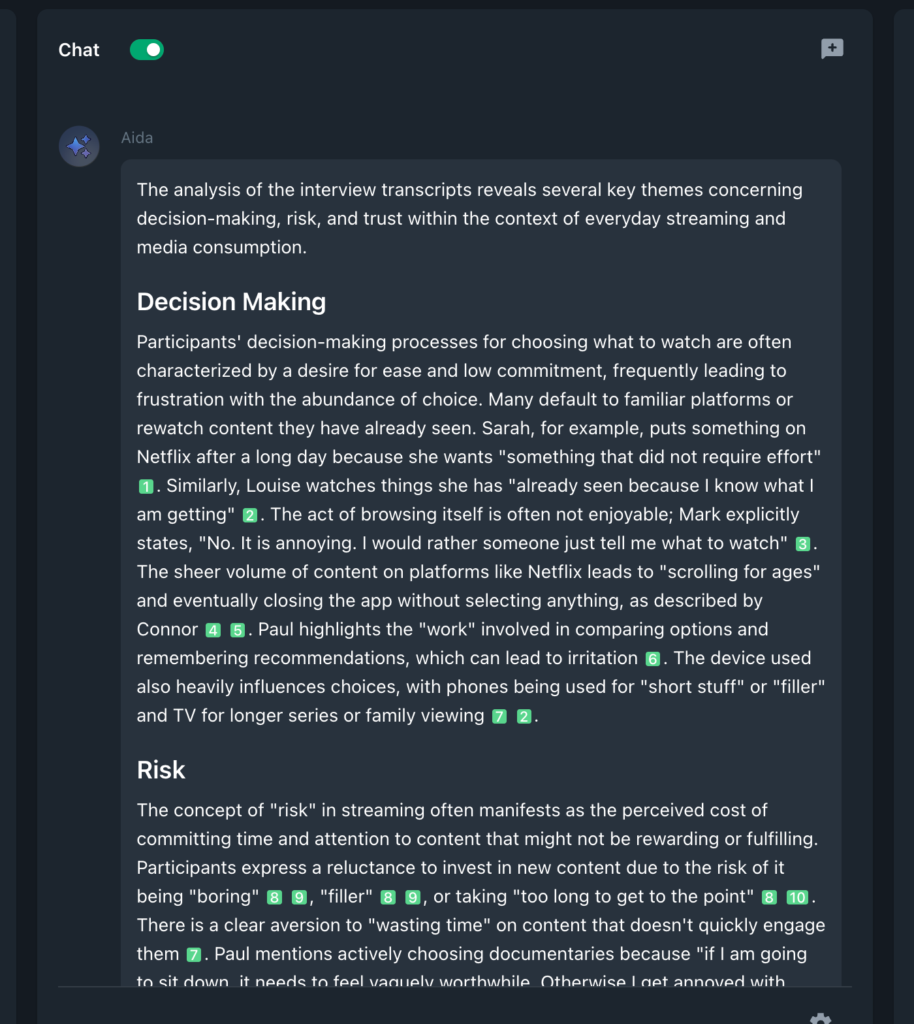
By keeping analysis grounded in a closed corpus and visible workspace, Beings mirrors established qualitative research practice. Insight remains connected to evidence. Interpretation remains accountable. Control stays with the researcher.
How to ensure privacy when using an AI tool for research
In Beings, decisions about privacy and data handling come before decisions about AI capability. Researchers set the level of data protection required first, and AI operates within those boundaries. For many teams, the primary concern is not how powerful a model is, but how far their data is allowed to travel. Strong prompting cannot compensate for unsafe data handling. If research data is already outside the researcher’s control, no amount of careful instruction can restore accountability.
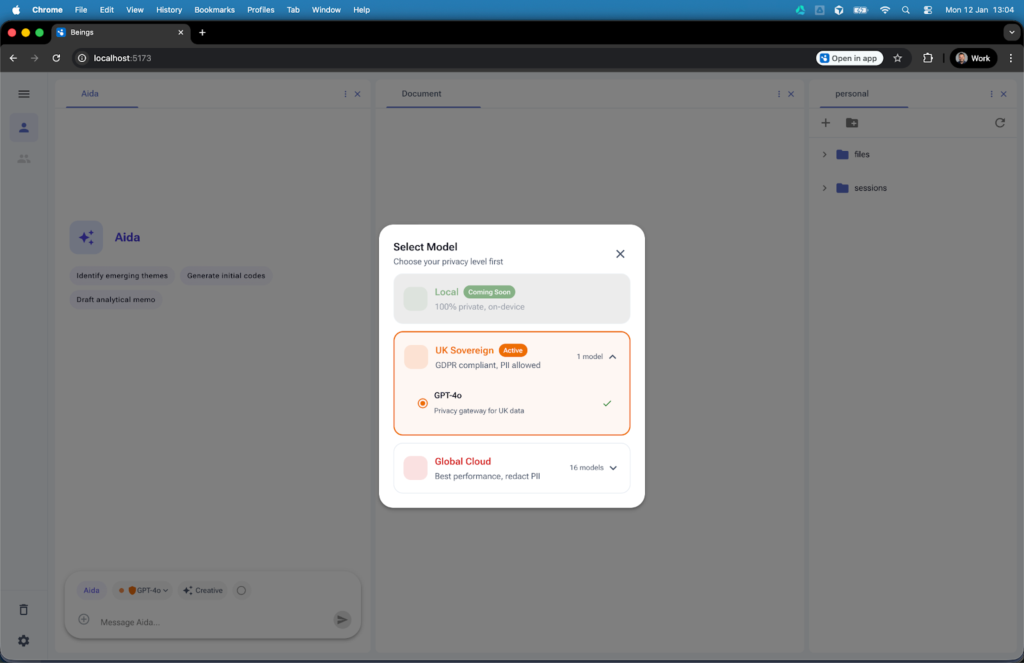
Within Beings this is made explicit through a traffic-light system that links privacy level directly to processing behaviour. When you use Beings you have the choice to determine which AI model you used, based on where data is processed within that model. This works on a traffic-light system where you can choose from the below settings:
Local (coming soon)
Your research files live on your device, not our cloud. We provide secure, ephemeral AI processing that returns insights to your local vault without retaining your data.
UK Sovereign (default)
Data is processed using UK-based infrastructure. Personally identifiable information remains under UK jurisdiction, and analysis, including search and retrieval, takes place within defined geographic boundaries.
Global
Only anonymised data is permitted. Automatic redaction is enforced, and users are warned before any data crosses jurisdictional boundaries, requiring an explicit decision to proceed.
Any movement across jurisdictional boundaries requires an explicit choice, reducing accidental exposure and removing the need for teams to rely on individual judgement under time pressure. These choices are visible within the workspace. Hovering over Aida shows which model is in use and the associated data handling rules, making sovereignty explicit rather than buried in settings or policy.
By separating privacy decisions from model selection, Beings treats sovereignty as a fixed condition rather than a user habit. UK-sovereign processing is the default, keeping jurisdiction explicit and accountability clear throughout the research workflow.
Data sovereignty features built into Beings
Beings enforces data sovereignty through product features designed specifically for qualitative research, rather than relying on policy, training, or individual judgement. Together, these features keep research data contained, visible, and governed throughout analysis.
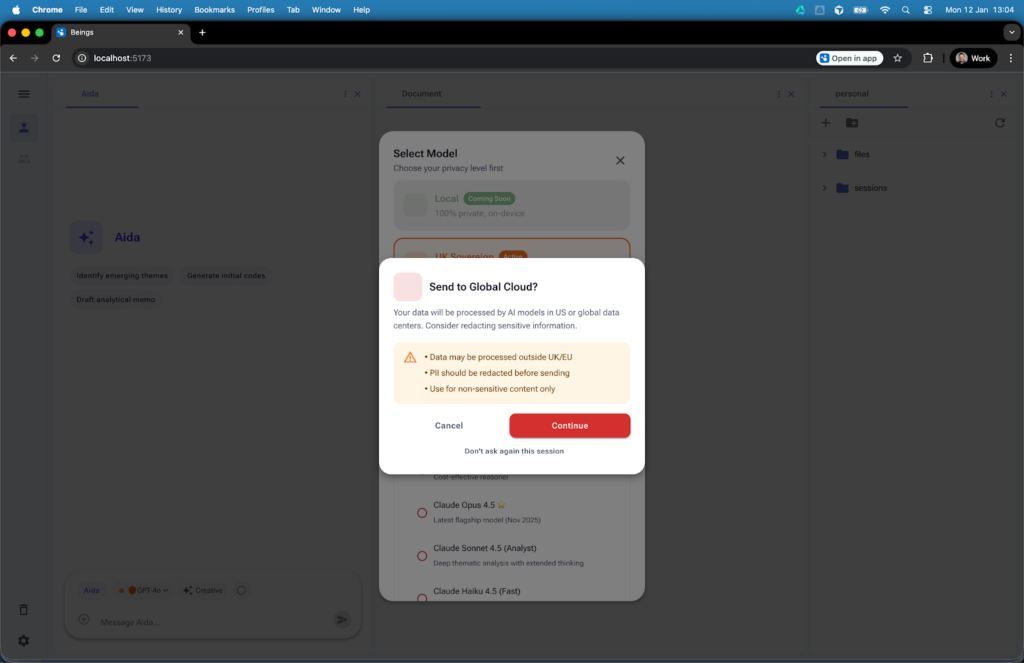
Airlock: controlled data movement
The Airlock governs how research data is routed between AI models and infrastructure. If the analysis involves systems outside the UK, Beings does not proceed silently. Researchers are shown a clear warning and must actively choose to continue. Data cannot cross jurisdictional boundaries without explicit consent, making risk visible at the moment it matters, including for junior team members.
Offline-first analysis
For projects that require maximum containment, Beings supports an offline-first mode. Analysis runs directly in the researcher’s environment, with research material held in local storage rather than sent to external servers. This removes cloud involvement entirely for sensitive work.
UK-sovereign processing and search
By default, Beings processes data using UK-based infrastructure. Personally identifiable information remains under UK jurisdiction, and analysis takes place within defined geographic boundaries. This applies not only to analysis, but also to search and retrieval. Queries against research data operate on UK-based systems and do not leave UK jurisdiction.
Zero training guarantee
Beings applies a zero training guarantee to all AI processing. Research material is used solely to support analysis within the project it belongs to and is not retained or reused to train shared AI models. Participant data remains bound to the context it was collected for.
Infrastructure pinning
These safeguards are reinforced through infrastructure pinning. Beings’ backend systems are technically and contractually tied to UK-based infrastructure, ensuring sovereignty is enforced by system design rather than inferred from provider assurances.
Together, these features mean sovereignty is not something researchers have to remember to apply. It is the condition the system starts from. Data movement is deliberate, visible, and constrained, giving agencies a clear and defensible account of how participant data is protected once AI becomes part of the workflow.
Why data sovereignty is a decision that agencies cannot outsource
For agencies, sovereignty goes beyond legal compliance. It affects client trust, procurement confidence, and the ability to stand behind research methods when they are questioned. Agencies are increasingly asked to explain not just what they found, but how data was handled at every stage of the process. Vague references to third-party tools or default settings rarely hold up under scrutiny.
AI makes this harder when convenience obscures visibility. Data movement is hidden, choices are implied rather than explicit, and responsibility drifts from systems to individuals. Over time, this creates a gap between what agencies believe is happening and what their workflows actually allow. Sovereignty cannot sit in a buried setting or a terms-of-service clause. It requires a clear decision about where data lives, which laws apply, and who controls the systems processing it.
This is the position Beings is built to support. It allows research teams to use AI without giving up control or explaining infrastructure decisions after the fact. For agencies working with sensitive qualitative data, sovereignty defines how research should be conducted.
If you want to see how this works in practice, you can try Beings for free and explore qualitative analysis within a safe, UK-sovereign research environment.
Data sovereignty FAQ for qualitative research
What is data sovereignty in qualitative research?
Data sovereignty in qualitative research refers to which country’s laws govern research data while it is collected, stored, processed, or analysed. For UK qualitative research, this matters because interview transcripts, focus groups, and open-ended responses are often collected under ethical approval and client confidentiality. When data stays within the UK, it remains subject to UK data protection law and regulatory oversight. Once it is processed outside the UK, different legal frameworks apply.
Can ChatGPT be used for qualitative research data?
ChatGPT is a general-purpose AI tool and is not designed specifically for handling sensitive qualitative research data. Paid business plans state that customer inputs are not used to train shared models by default, but data is still processed within public cloud infrastructure operated by a third party. For qualitative research involving participant data, client-owned insight, or regulated sectors, using ChatGPT can reduce visibility and control over where data is processed and which laws apply.
Does Beings AI train models on qualitative research data?
No. Beings AI does not use qualitative research data to train shared AI models. Data is processed solely to support analysis within the specific research project it belongs to and is not retained or reused for model improvement. This keeps participant data confined to its original research context.